
Develop Agent Skills Like Software
Your rep just left a customer meeting. A voice agent intercepts them. Four minutes later, the deal intelligence is captured — or it isn't. That depends entirely on the skill driving the debrief.

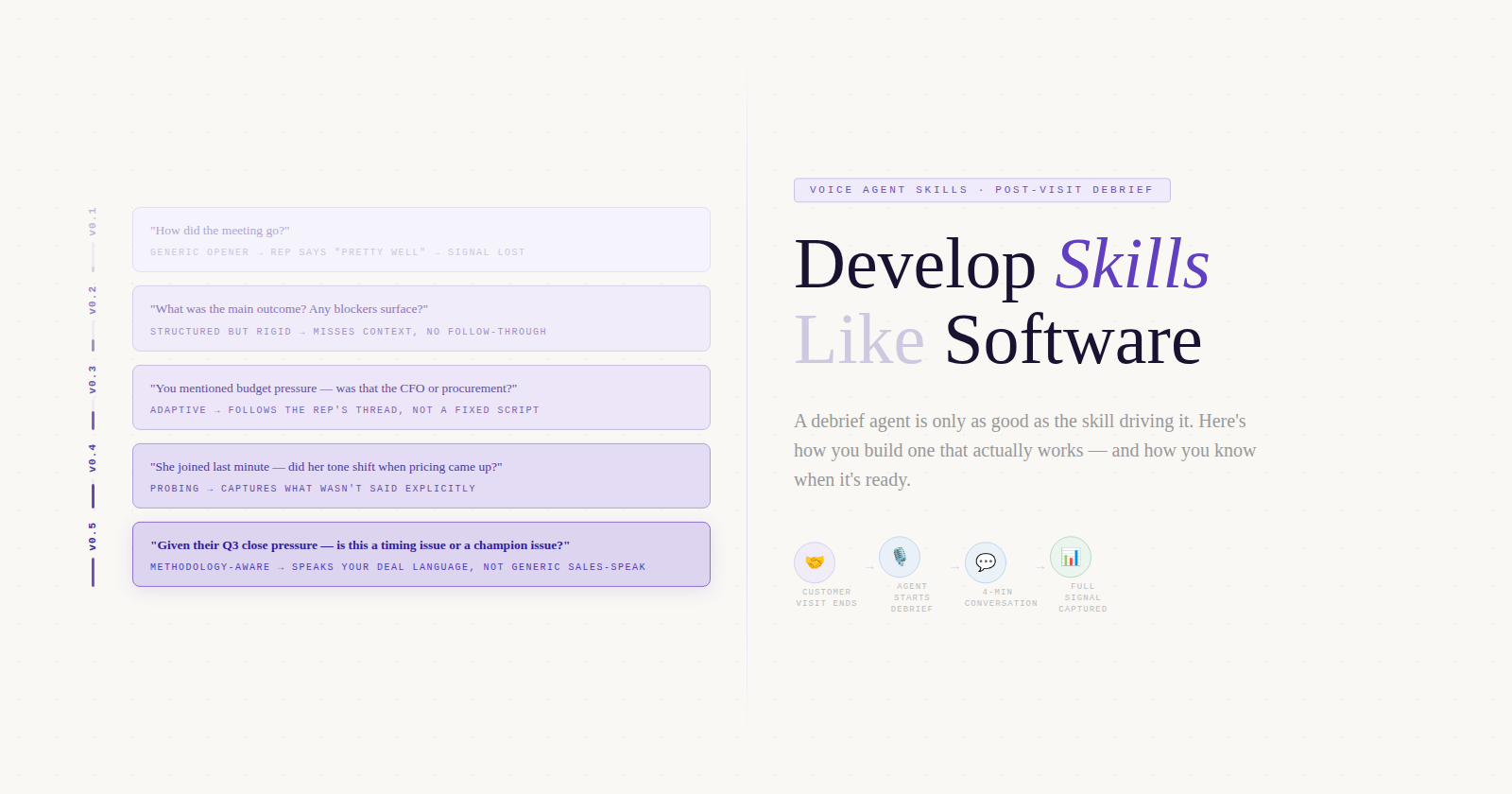
The technology behind a post-visit voice debrief is not the hard (est) part. A voice agent that calls your rep after they leave a customer meeting, conducts a structured conversation, and pushes the output into your CRM. What determines whether it actually works is the skill driving the debrief: the questions it asks, how it adapts when a rep gives a vague answer, when it probes deeper versus moves on, and whether it’s speaking in the language of your deal methodology rather than generic sales-speak.
A write-once skill produces a write-once debrief. Your rep says “it went pretty well” and the agent moves on. The signal is lost before the car park exit. A skill developed through iteration does something completely different: it follows the thread, asks the follow-up that unlocks the real answer, and surfaces the concern the rep didn’t even know they should name.
In The Skills Trap, I laid out the Skill Fidelity Spectrum — Zone 1 tasks where borrowing a generic skill is rational, Zone 2 workflows where the fit starts to matter, and Zone 3 strategic work where a borrowed skill is a liability. A post-visit debrief for anything beyond a cold intro call is firmly Zone 2 or Zone 3 territory. The methodology can’t be borrowed. Neither can the instinct for when to push.
Why the debrief skill is different from a transcript skill
A skill that analyses a transcript is reactive — it reads what happened and extracts structure. A debrief skill is active. It’s conducting a conversation in real time, making decisions about what to ask next based on what the rep just said. That’s a fundamentally different challenge.
With a transcript skill, the information is already in the source. With a debrief skill, the information is locked inside the rep’s head — and the skill’s job is to draw it out through the right sequence of questions. If the skill asks the wrong question, or moves on too quickly, the signal is simply never captured. There’s no transcript to go back to.
This is what makes iteration so important. A debrief skill written once reflects one mental model of how a post-visit conversation flows. In reality, every rep is different, every meeting lands differently, and the skill that works brilliantly with a rep who gives full structured answers will completely fail with the rep who says “it was fine, they seemed keen” and waits for the next question.
The skill at v0.1
Here’s what a first draft looks like — reasonable on paper, dangerous in the field:
SKILL.md — post_visit_debrief / v0.1
Trigger: After a rep completes a customer visit or call, conduct a structured
debrief conversation to capture deal intelligence.
Conversation flow:
1. Ask how the meeting went overall
2. Ask what topics were discussed
3. Ask about any objections or concerns raised
4. Ask about next steps agreed
5. Confirm the output before ending
Output fields:
- sentiment: positive | neutral | negative
- topics_discussed: list
- objections: list
- next_steps: list with owner and deadline
- summary: 2–3 sentence narrative
# Be conversational. Keep it under 10 questions.
# If a field isn't covered, return null — don't guess.
This looks structured and sensible. Run it across twenty real post-visit debriefs and it falls apart in ways that are impossible to see from the desk.
Cycle 1: what breaks in the field
🔴 Failures Observed
Generic openers produce generic answers. “How did the meeting go?” is the worst possible first question. It licenses a one-word answer. “Pretty well” ends the thread before it starts. The skill has no ability to go deeper because it doesn’t know what it was hoping to find.
Fixed sequence ignores what the rep just said. The skill moves through its five steps regardless of what surfaces. When a rep mentions the CFO joined unexpectedly, the skill asks “what topics were covered?” instead of “what shifted when she walked in?”
Implicit signals are never surfaced. Reps rarely say “there’s a competitor threat.” They say “they mentioned they’ve looked at a few options.” The skill doesn’t probe this — it moves to the next fixed question and the competitive intelligence evaporates.
Single sentiment field is worse than nothing. A meeting where the prospect loved the product but the CFO has a Q3 budget freeze gets rated “positive.” That’s not just unhelpful — it’s actively misleading. The rep logs it as a warm deal. It stalls for two months.
Monosyllabic reps kill the output entirely. Some reps are not natural debriefers. They answer in three words and wait. The skill accepts the short answer and moves on, producing a summary with four null fields and two useless ones.
✅ Cycle 1 → v0.2 — Targeted Fixes
Replace generic opener with context-aware entry. The skill now opens with a specific question derived from CRM context: “You were meeting with [contact] at [company] — was this the first time you had the economic buyer in the room?” This immediately signals the agent knows the deal.
Replace fixed sequence with adaptive branching. The skill now follows the rep’s thread rather than a script. If the rep mentions someone unexpected, the skill probes that before moving on. If pricing came up, the next question is about reaction to pricing — not “any objections raised?”
Add implicit signal detection rules. Phrases like “looked at other options,” “current setup,” “existing vendor” trigger a follow-up probe: “When they mentioned that — was that a concern or just context?” This turns ambient language into captured signal.
Split sentiment into tone and deal risk.
call_tonecaptures emotional register.deal_riskcaptures signals that threaten progression regardless of how warm the meeting felt. A deal can have positive tone and high risk.Add handling strategy for short answers. If a rep answers in fewer than eight words, the skill reframes the question from a different angle rather than accepting the short answer and moving on.
Cycle 2: what the fixes unlock
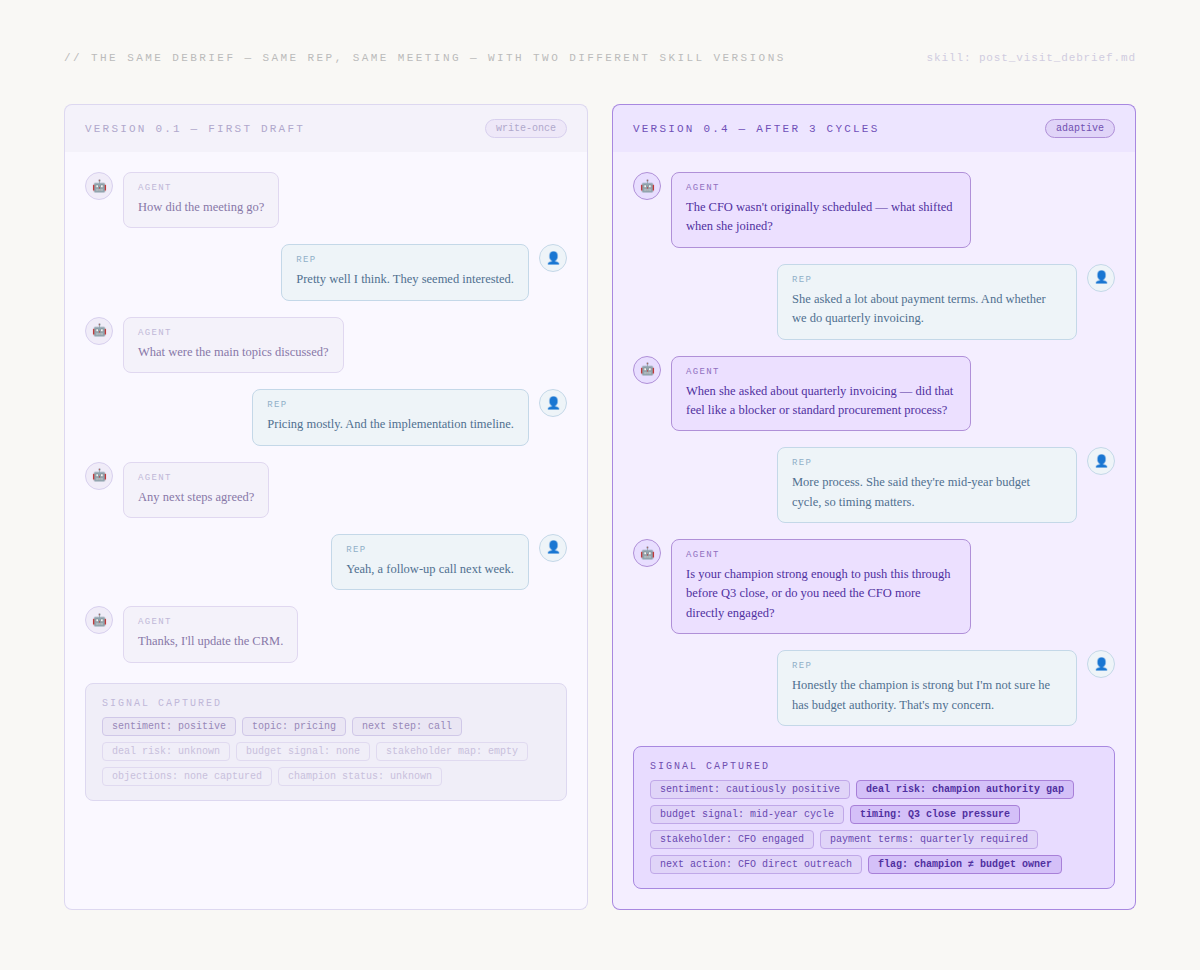
v0.2 is significantly better — and significantly more revealing. The adaptive branching is working, but the skill is occasionally going too deep on a single thread, spending five exchanges on payment terms at the expense of never covering competitor positioning or champion strength. The context-aware opener is good but relies on CRM data being current — when it isn’t, the opening question misfires.
Cycle 2 fixes: add a thread depth limit — no more than three consecutive exchanges on a single topic before the skill explicitly pivots. Add a CRM data quality check with a fallback opener. Add coverage balance logic — the skill tracks which output fields are still null and ensures coverage before closing.
By cycle 3, you’re not fixing structural failures. You’re calibrating for the rep who gives excellent answers then runs out of things to say. You’re handling the meeting that ended badly, where the rep is defensive. You’re tuning for industry vocabulary differences. These are edge-case calibrations, not fundamental problems. That’s the signal you’re approaching production-ready.
Where Auron sits in this loop
This is the workflow Auron is built to support. On the platform, voice agents deploy for post-visit debriefs with skills you define from scratch in your methodology’s language, develop iteratively against real debrief conversations, or import from a starting point and adapt to your specific context. The platform surfaces where your skill produces inconsistent outputs, traces failures to specific instructions, and tracks quality across versions — so the dev loop runs in days, not months.

The red-team round
After cycle 3 or 4, deliberately try to break the skill with the hardest scenarios: the rep who just had a bad meeting and doesn’t want to debrief. The rep who gives textbook answers that don’t reflect what actually happened. The meeting that ended ambiguously with no next steps agreed. The enterprise visit with seven people in the room and the rep can only remember four of them.
Skills that survive this degrade gracefully under pressure. They surface uncertainty rather than manufacturing false confidence. They know when to close a thread that’s going nowhere. That graceful degradation matters enormously when the skill is running across your entire sales team, unsupervised, after every customer visit.
What you’re really building
The hero image at the top of this article shows the skill evolving from “How did the meeting go?” to “Given their Q3 close pressure — is this a timing issue or a champion issue?” That progression represents accumulated understanding that can only come from running the skill against real reps, on real conversations, and learning from what breaks.
After five cycles, you know which questions reliably unlock signal. You know how to handle the monosyllabic rep and the over-talkative one. You know what your skill does when it encounters a meeting type it wasn’t designed for. That’s not something you can write in a first draft. It’s something you earn through the loop.
Zone 2 and Zone 3 debrief skills are the ones that compound — across your team, your pipeline, your organisation’s collective understanding of every customer conversation. But compounding only starts when the foundation is solid. And the foundation is only solid when you’ve stopped writing and started iterating.
Build the skill. Deploy it. Watch what breaks. Fix what broke. Repeat until you’ve moved from fundamental failures to edge-case calibrations. That’s when it’s ready — and not before.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organisational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.