
Workflows or autonomy: which “agent” did you actually ship?
Most production “agents” are workflows with one LLM in the loop. That’s frequently the right architecture. The bug is the label.

Most teams ship workflows and call them agents. The label is downstream of the demo, not the architecture — and once procurement has heard the word “agent” said in the room enough times, the rest of the conversation runs on the wrong assumptions. You can’t have an honest reliability conversation about something that’s been mis-named at the door.
This isn’t a hype problem, exactly. It’s a taxonomy problem. There are at least four different things that get called “agent” in production right now, and they fail in completely different ways. Knowing which one you actually shipped is the first move in not missing your SLAs, not getting blindsided by the invoice, and — selfishly — not spending six months trying to fix the wrong layer of the stack.
The four modes
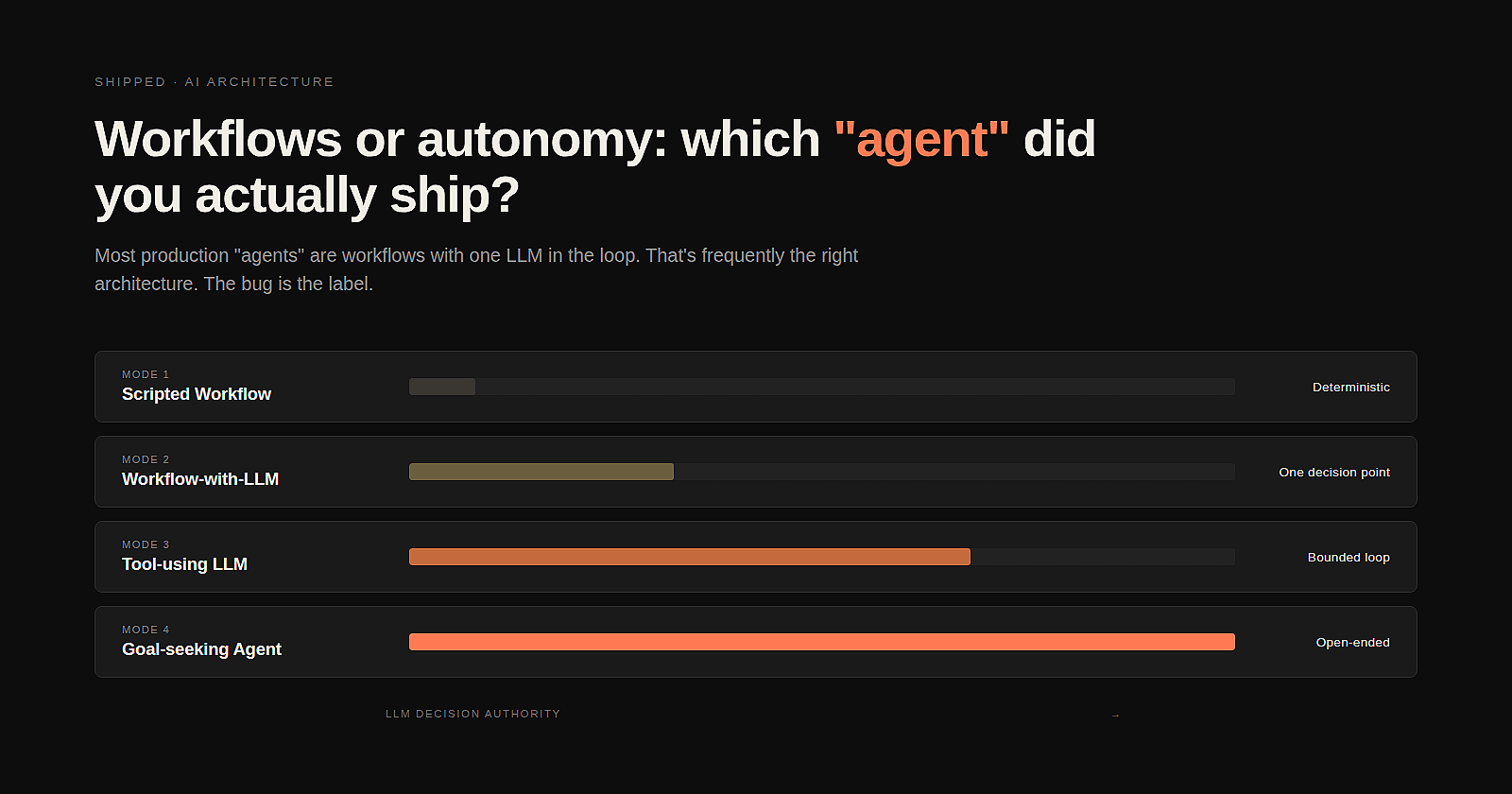
Here’s the taxonomy. Before reading further, map your last release to one of them.
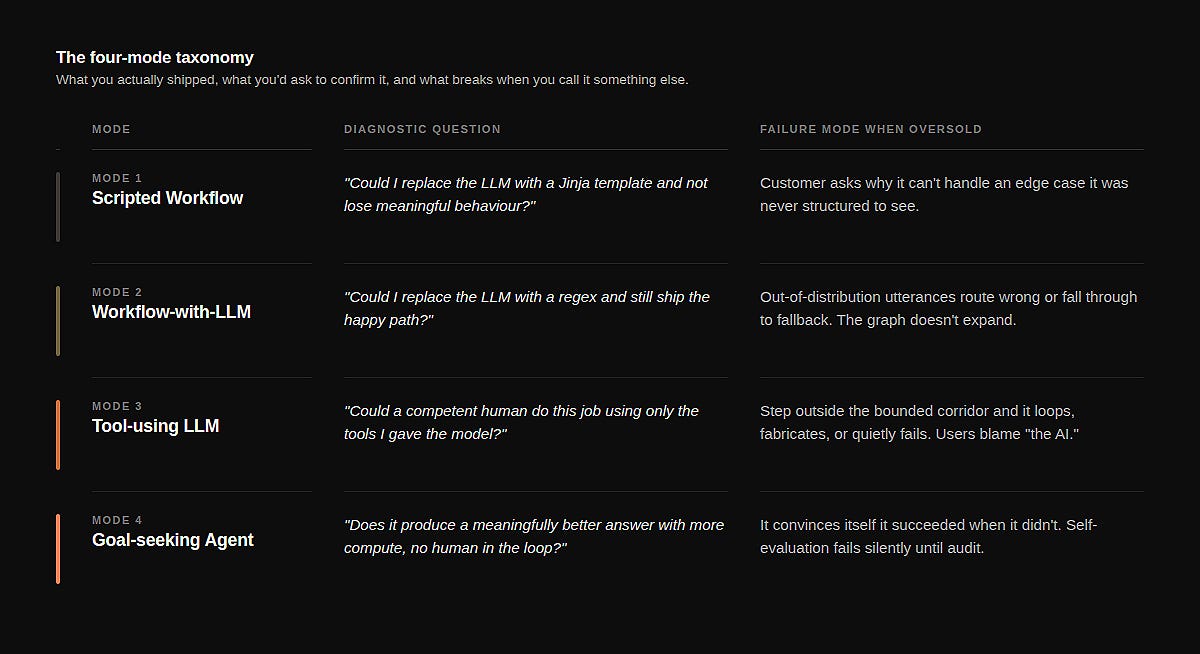
Mode 1 — Scripted Workflow. Deterministic end to end. The LLM appears nowhere, or only at the surface — generating a confirmation email, summarising a record after the work is done. Pull the LLM out and replace it with a templated string. Nothing meaningful breaks. The system still does its job.
Diagnostic: could you replace the LLM with a Jinja template and not lose meaningful behaviour? Failure mode when oversold: the customer asks why it can’t handle an edge case it was never structured to see. You answer “the model didn’t pick up on it,” which is true and irrelevant — the model was never in the decision loop.
Mode 2 — Workflow-with-LLM. Deterministic almost end to end, with one or two LLM calls at decision points. Classification, extraction, intent detection, routing, summarisation-at-decision-time. The graph is hard-coded; the LLM only resolves a step. This is what most production “agents” are.
Diagnostic: could you replace the LLM with a regex (or a small classifier) and still ship the happy path? If yes, you’re here. Failure mode when oversold: you promise the system “understands” the customer. It doesn’t — it classifies their utterance and routes. When the utterance falls outside the distribution you trained on, the workflow doesn’t gracefully expand. It routes wrong, or it routes to fallback, and the customer feels the brittleness.
Mode 3 — Tool-using LLM. The LLM is in the loop, makes the next-action decision each turn, and chooses from a curated tool set. But the scope is bounded — the system prompt fixes the role, the tool set is small and stable, and the loop has a defined termination condition. Most production “copilots” live here. So do most coding agents.
Diagnostic: could a competent human do this job using only the tools you’ve given the model, in roughly the same number of turns? Failure mode when oversold: you promise it “figures things out.” It does — within the corridor you built. Step outside the corridor and it loops, fabricates, or quietly fails. Users blame “the AI.” The thing that was bounded is the architecture.
Mode 4 — Goal-seeking Agent. Given a goal, the LLM plans, decomposes, executes, evaluates its own progress, replans, and may spawn sub-agents. The tool set is open or discoverable. The number of turns is unbounded in principle. The system is structured to keep going until a self-assessed success criterion is met.
Diagnostic: does it produce a meaningfully better answer if you give it more compute, with no human steering the loop? If yes, it might be Mode 4. Most things in production that claim Mode 4 are Mode 3 with longer loops. Failure mode when oversold: it convinces itself it succeeded when it didn’t. Self-evaluation is the hardest problem in the stack, and the failure is invisible until someone audits the work.
The label gap
The honesty problem is that all four modes can look identical in a demo. The demo is scripted, the inputs are curated, the failure modes are out of frame. By the time procurement sees it, “agent” has been said enough times that nobody asks which mode it is. Which matters concretely, in three ways.
Reliability targets are mode-specific. A Mode 2 workflow has a measurable, finite test surface — you can enumerate the inputs at each branch and run them. A Mode 4 system doesn’t, because the path space explodes. The SLAs you can credibly offer differ by orders of magnitude across the modes. Selling Mode 2 reliability for a Mode 4 architecture is how teams miss their first quarter’s targets.
Failure attribution is mode-specific. When a Mode 2 system fails, it’s almost always a routing error or a misclassification — fixable with a labelled example or a prompt tweak. When a Mode 3 system fails, it’s a tool-design or loop-termination problem. When a Mode 4 system fails, it’s a self-evaluation problem and there is no quick fix. If your team is fixing the wrong layer, you’re spending engineering cycles in the wrong place.
Cost models are mode-specific. Mode 2 has bounded per-transaction LLM cost. Mode 4 doesn’t. You will be surprised by your invoice if you priced like the first and shipped like the fourth.
The case for shipping a workflow on purpose
The reflex when someone shows you a Mode 2 system is to call it primitive. It isn’t. In a lot of cases, Mode 2 is the most honest architecture available given the constraints of the domain.
If you’re in compliance-heavy enterprise, the path space should be bounded. Auditability requires it. The reason your invoice processing system isn’t a goal-seeking agent is that the regulator wants to know what it will and won’t do, with high confidence, before you deploy. A workflow with an LLM at the classification step gives the auditor an answerable question. A Mode 4 agent doesn’t.
If you’re in customer support, the cost-to-quality curve flattens around Mode 2 or Mode 3 for the vast majority of tickets. The handful of cases that would benefit from full Mode 4 reasoning are also the handful where you want a human in the loop anyway. The right architecture is the simpler one with a good escalation path, not the more impressive one with worse worst-case behaviour.
The strategic question isn’t “are we using a real agent?” — it’s “what is the lowest mode that does this job acceptably, and have we built clean handoffs to higher modes for the cases that need them?”
Most teams I’ve watched ship better systems by moving down the stack from where they started — taking a Mode 3 implementation and refactoring it into a Mode 2 workflow that calls Mode 3 only at the steps that genuinely need it. That’s not a downgrade. That’s the right answer arriving on the second draft.
The procurement conversation
So how do you actually use this? Two moves.
Name the mode in your internal documentation before you talk to anyone externally. “We shipped a Mode 2 workflow with two LLM decision points” is a statement that survives contact with a postmortem. “We shipped an agent” doesn’t survive contact with a customer who has read a Sequoia blog post.
In the procurement deck, swap “agent” for the mode-honest description in at least one slide. Marketing won’t love it. The alternative is a deal that closes on Mode 4 expectations and a renewal that fails on Mode 2 reality. There’s a workable middle path: keep “agent” in the brand, but spell out in the body of the proposal exactly what decision authority sits with the LLM, what’s deterministic, and where the loop terminates. The procurement team that knows the difference will close faster. The procurement team that doesn’t will at least have the document on file when things go sideways, which protects both sides.
The takeaway
The reliability conversation can’t happen until the labelling conversation happens. As long as “agent” is a marketing word that compresses four very different architectures into one bucket, the field can’t have an honest conversation about what works, what fails, and how to improve it. The piece you can actually do, on the system you actually shipped, is to be precise about which mode it is. Once everyone in the room knows that, the rest of the conversation — what to measure, what to fix, what to promise — gets a lot easier.
Most “agents” in production are workflows. That’s fine. Ship the workflow. Call it a workflow. Then have the reliability conversation it deserves.
The author is an AI Engineering Leader, helping Enterprise finance, revenue, and operations teams ship AI into production — and measure whether the bets actually paid off. Keen to engage !