
Voice AI Doesn’t Have a Per-Minute Cost

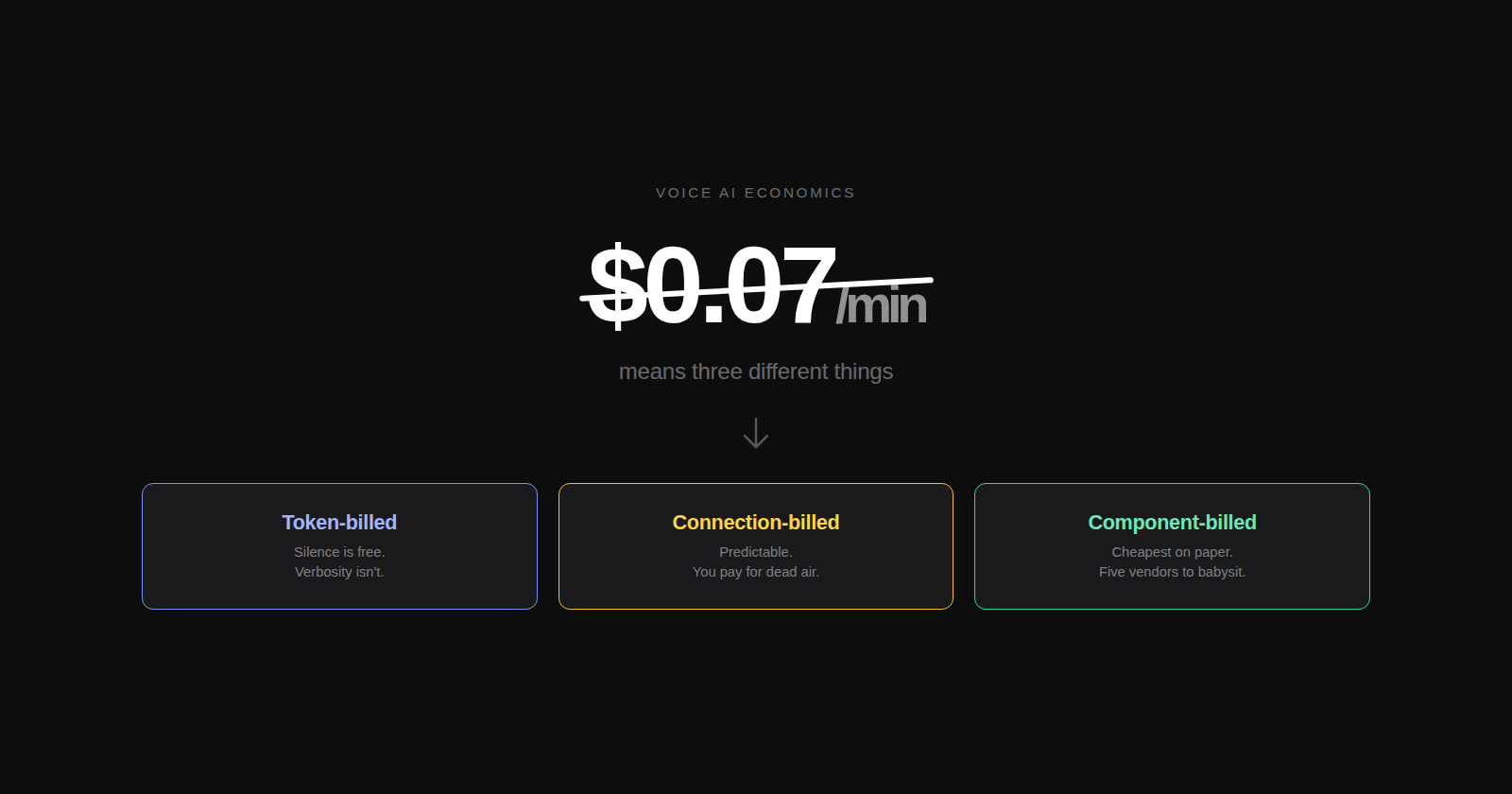
Open any voice AI comparison post and you’ll see the same table. OpenAI Realtime: ~$0.10/min. Deepgram Voice Agent: $0.07/min. Retell: $0.07/min. Vapi: $0.05/min. ElevenLabs Agents: $0.12/min.
The numbers look comparable. They’re not.
What looks like five rows of the same metric is actually three structurally different billing models. Each meters something different. Each scales differently with conversation length, verbosity, and silence. Depending on what kind of voice agent you’re building, the same headline number can mean radically different real bills — sometimes by a factor of three or four.
If you only compare per-minute rates, you’ll consistently pick wrong.
Three meters, dressed up to look like one
Voice AI has converged on three architectural shapes, and each one bills against a different unit:
Token-billed speech-to-speech. A single multimodal model takes audio in and emits audio out. OpenAI Realtime, Gemini Live, and the next generation of native-audio models. The bill is paid in tokens — audio tokens for input and output, text tokens for system prompts and conversation history. Crucially, only response generation is billed. If a user pauses for ten seconds to think, those ten seconds are essentially free. But every turn carries the full accumulated context, and the system prompt rides on every response, so a long conversation gets quadratically expensive in carry-over.
Connection-billed bundles. Deepgram Voice Agent, ElevenLabs Agents, Retell. These wrap STT, LLM, and TTS into a single API. The bill is paid in connection-time — wall-clock seconds the WebSocket is open, regardless of who’s talking. Silence costs the same as speech. A 10-minute call with three minutes of useful conversation costs the full ten. Predictable, but only kind to certain conversation shapes.
Component-billed cascade. You stitch your own pipeline: Deepgram or AssemblyAI for STT, your LLM of choice, ElevenLabs or Cartesia for TTS, LiveKit or your own orchestration. The bill is the sum of components, and you can drive it down toward $0.05/min in raw compute. But the operational bill — engineers, monitoring, fallbacks, prompt tuning across four vendors — is invisible in the per-minute math.

The advertised numbers all sit in the $0.05 to $0.15 band. Look at what each meter actually measures, though, and they’re not the same animal.
Conversation shape decides the architecture
The right question isn’t “which is cheapest.” It’s “which billing model matches what my agent is actually doing.”
Three illustrative shapes make this concrete.
The fast IVR. “Press one for your balance, two for a transfer.” Three-turn conversation, total length under ninety seconds, mostly the agent talking. Silence is rare. Conversation memory is irrelevant — each call is stateless. Connection-billed bundles win cleanly here. Deepgram or Retell at $0.07/min is predictable, the bundled simplicity removes engineering load, and there’s no idle time to pay for. Token-billed S2S is overkill for a script-shaped agent, and a cascade adds operational cost the workload doesn’t justify.
The thoughtful interview. A debrief, an intake interview, a clinical history-taking. Long pauses while the human thinks. State accumulates across turns — earlier answers shape later questions. The conversation runs fifteen to twenty-five minutes. Token-billed S2S structurally wins. Silence is free, which matters enormously when you’ve designed the agent to want the human to think before answering. The cost of carrying state through context windows is real, but with prompt caching it stays bounded — and the alternative, paying connection-time for ten minutes of intentional silence, is a worse trade.
The listening co-pilot. A voice agent that sits inside an hour-long meeting or sales call, surfacing insights and escalating signals. Almost entirely listening. Component-billed cascade is the only sensible option. You don’t want to pay $0.07/min × 60 minutes = $4.20 to a connection-billed bundle for an agent that mostly transcribed. Only STT model for example at $0.0077/min × 60 minutes is forty-six cents, plus a small LLM cost on the actual signal extraction. The ratio between bundle pricing and component pricing on listening-heavy workloads is roughly ten-to-one.

The three architectures aren’t competing for the same workload. They’re optimizing for different conversation shapes.
Picking by headline rate without knowing the shape is how teams end up with bills three to five times what their pricing-page math predicted.
What this changes about how you choose
Three rules of thumb that the per-minute table can’t tell you:
If the agent has long pauses by design, bill by tokens, not connection. A connection-billed bundle penalizes the exact behavior the design depends on. The user’s thinking time is the product, and you don’t want to charge for it.
If the conversation is mostly listening, don’t pay LLM-bundle prices to act as a transcription pipe. Cascade. The bundle’s value is in the LLM-driven response loop, and a co-pilot agent isn’t running that loop most of the time.
If the agent is short, scripted, and stateless, don’t pay for a token-priced model whose strength is context retention. Take the bundled simplicity. Pay for predictability over flexibility, because the workload doesn’t reward flexibility.
The voice AI market is converging (as of now…) at around $0.05 to $0.15 per minute for raw conversation, regardless of architecture. The cost differentiation that will matter over the next eighteen months isn’t the headline rate — it’s whether the agent’s design is structurally aligned with how its provider bills.
The per-minute number was always a marketing artifact. The architecture is the actual economic decision.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organizational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.