
Tokens Are Not Outcomes
Token spend is becoming the "usable" measure of AI productivity inside engineering orgs. It’s a useful signal. Here’s what it takes to turn it into something you can actually act on.

↳ This piece is a companion to Your Pricing Model Is a Confession — an argument that what AI vendors charge for reveals exactly what they believe they can be accountable for. The same logic surfaces here, on the buyer side of that equation.
Companies are starting to measure AI productivity by counting tokens. The logic is intuitive: more tokens consumed means more AI engaged, more work done, more value created. Zapier flags engineers whose token use runs 5x higher than peers as a point for investigation. Vercel reports a single engineer spent $10,000 in tokens in one day — and the CEO says it compressed months of work and saved the company millions. Boards want dashboards. The token is having its moment as the new unit of productive effort.
The instinct is right. Measuring AI engagement matters. But token spend is a measure of input intensity, not output value — and conflating the two is going to cause real problems as organizations build performance systems on top of it.
What the $10K Story Actually Proves
The Vercel case is striking. One engineer, $10,000 in tokens, one day, months of infrastructure work compressed into hours. The CEO says it saved millions. That’s probably true. But notice what’s doing the work in that sentence: the CEO’s judgment, not the token count.
The token count tells you inputs were consumed at scale. The CEO’s assessment — grounded in domain knowledge, context, and an understanding of what that infrastructure was actually worth — tells you those inputs translated to business value. Those are two different claims. Only one of them is in the data.

Token usage can’t tell you whether the right problem got solved, whether the solution will hold six months from now, whether it introduced technical debt that will cost three times as much to unwind, or whether a different engineer spending $200 on a different problem would have created more value. The $10K story is compelling precisely because the human judgment closing the attribution loop is unusually clear. Most token stories won’t have that. They’ll just have the number.
Four Things to Build Before Token Spend Becomes a Score
The gap between token spend and business value isn’t a data problem — it’s an epistemic one. Here’s what actually needs to be in place before token tracking can meaningfully inform performance assessment.

01 — A precise definition of the outcome Not “the work went well” — something specific enough to be falsifiable. For engineering, this means agreeing in advance on the problem class being attacked and what resolution looks like: Feature Velocity, P2 bug resolution time on service X, deployment frequency for team Y, reduction in incident MTTR. Without this anchor, token spend floats free. High consumption against an ill-defined problem is indistinguishable from high consumption against a well-defined one.
02 — Attribution infrastructure that can isolate AI’s contribution Even when outcomes are defined, isolating the AI’s role is hard. The engineer’s judgment, the quality of the prompt, the clarity of the ticket, the underlying architecture — all co-produce the result. Attribution infrastructure means having baselines before AI engagement, controlled comparisons where possible, and enough instrumentation to separate signal from confound. Without it, you’re attributing outcomes to token spend that were partly or mostly driven by other factors.
03 — Organizational consistency in how the definition is applied Outcome definitions only hold if applied consistently across teams and review cycles — stable enough to survive manager turnover, re-orgs, and the natural drift of how “good work” gets described. Without this, token metrics get gamed: engineers optimize for the measurable proxy rather than the underlying outcome. The definition needs to be organizational policy, not individual manager interpretation.
04 — A scope narrow enough that the loop can actually close The broader the team’s mandate, the more diffuse the impact. Attribution works best when the loop is tight — one team, one problem class, one measurable output stream. Horizontal teams with wide remits make fair attribution nearly impossible: the AI’s contribution is one thread in a tapestry of dependencies, and pulling it out cleanly is more art than science.
These aren’t new requirements invented for the AI era. They are the same requirements that have always separated meaningful engineering metrics from vanity ones. What’s new is the pressure to skip them — because the token data is right there, it’s quantitative, and it arrives before any of this infrastructure exists.
Where Engineering Has an Advantage Over the Pricing Side
In the companion piece on AI vendor pricing, the argument was that per-credit billing confesses the same uncertainty: “we charge for attempts, whether they worked is not our contract.” The structural parallel is real — both are cases of counting inputs while the output measurement infrastructure catches up.
But the two cases are not identical, and the difference matters for how quickly the attribution gap is likely to close.
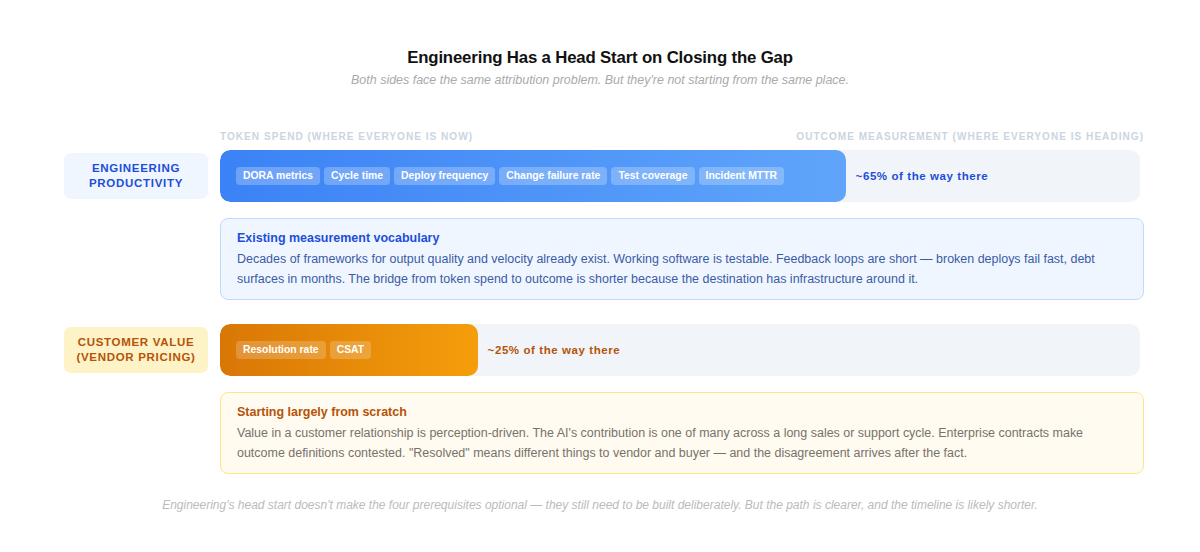
Engineering side: The vocabulary for measuring output quality and velocity has existed for decades. DORA metrics, cycle time, PR review rates, deployment frequency, change failure rate — these are established frameworks that can absorb AI signals as an additional input. Working software is testable. Code quality, test coverage, and incident rates are quantifiable in ways that customer perception simply is not. Feedback loops are shorter: a broken deploy fails fast, technical debt surfaces in months. The bridge from token spend to outcome is shorter here because the destination already has infrastructure around it.
Customer value side (vendor pricing): Whether an AI interaction “worked” in a customer relationship is partly perception-driven — shaped by buyer expectations, relationship dynamics, and context that no metric fully captures. The AI’s contribution is one of many in a long sales or support cycle, and isolating it from the human rep, the pricing, the timing, and the competitive situation is genuinely hard. Enterprise legal teams push back on outcome definitions in contracts; “resolved” means different things to vendor and buyer, and the disagreement arrives after the fact. The measurement infrastructure here is being built largely from scratch.
The implication: organizations investing in engineering attribution infrastructure now are working with a meaningful head start. The language for engineering quality already exists. The bridge is shorter. That doesn’t make the four prerequisites above optional — they still need to be built deliberately. But it does mean the path is clearer, and the timeline for closing the gap is likely faster than on the customer value side.
From Signal to Score — Getting the Sequence Right
Token tracking used as a leading signal — a prompt to look more closely, a way to surface anomalies worth a conversation — is genuinely useful. The Zapier approach of flagging 5x outliers for investigation, not verdict, is about right. The problem is when the token count moves from signal to score before the underlying measurement infrastructure exists to support that weight.
The organizations that get this right will define outcomes before they instrument inputs. They’ll use token data to ask better questions, not to answer the performance question directly. And they’ll be honest that the mandate to measure AI productivity has arrived well ahead of the infrastructure to do it fairly — which is itself useful information, if you’re willing to act on it.
Token spend is the new seat license. Everywhere soon. Insufficient on its own. The confession is the same — and so is the work required to move past it.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organizational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.