
The Ground Is Rising
AI capability improves faster than most teams build. The PM playbook built for stable technology needs to be rebuilt for an exponential.

There’s a failure mode quietly spreading across product teams right now, and it doesn’t feel like failure while it’s happening. You do the research, write the spec, lock the roadmap, and begin execution. Somewhere around month three or four, the model beneath your product improves — not incrementally, but by a meaningful step — and the constraint you spent two months designing and building around quietly disappears. The workaround you engineered is now just complexity. The feature you deprioritised because it “wasn’t feasible yet” is now table stakes for someone else who checked last week.
The traditional product management playbook is built on a foundational assumption: that what’s technologically possible at the start of a project is roughly what’s possible at the end. You gather information upfront, make confident bets about the future, then execute against a plan over weeks and months. Discovery happens before the roadmap locks. Stability is the precondition for good execution.
That assumption is broken. It has been for a while. Most teams just haven’t reorganised around that fact yet.
What exponential actually looks like in practice
METR, an AI safety research organisation, has been tracking what they call “task-completion time horizons” — essentially, how long a task a frontier model can reliably complete autonomously. It’s one of the cleaner proxies for raw capability we have.

That’s the jump in human-equivalent task capability over roughly 16 months — the same period as a single annual planning cycle. In late 2024, frontier models could handle tasks that would take a human around 21 minutes. By early 2026, they handle tasks that would take a skilled human nearly 12 hours.
That 41x number isn’t a marketing claim. It’s a measured capability shift. If your team set a roadmap in January 2025 and has been executing faithfully against it, there’s a real chance some of the constraints you built around have simply ceased to exist. Not degraded. Not loosened. Gone.
The concrete version of this: something that required a multi-step, carefully engineered pipeline to even attempt last year might now just work with a direct prompt. Features that got deprioritised as “technically not ready” are now ready — and your competitors who test more frequently have already shipped them.
The implication isn’t that planning is useless. It’s that the window between “we checked what’s possible” and “that’s no longer accurate” has compressed dramatically. Planning on a six-month horizon with a 16-month capability curve means you’re designing around a model that no longer exists by the time you ship.
The four shifts that actually matter
The teams adapting well to this environment aren’t doing something radically different. They’re mostly subtracting things: remove the long roadmap, remove the docs-first culture, remove the clever workarounds. What’s left is faster, lighter, and easier to update.
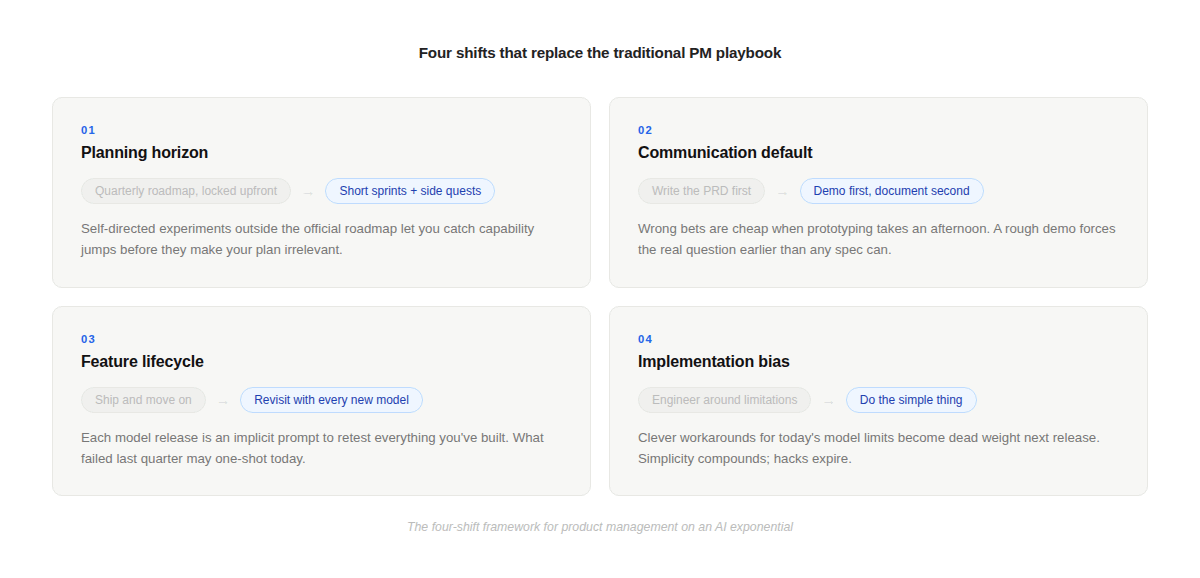
Short sprints and side quests. The most important change is to planning cadence. Long roadmaps locked upfront assume capability is stable. Short sprints with explicit room for self-directed experimentation — “side quests” that run outside the official plan — create the feedback loop you need to catch capability jumps before they make your plan irrelevant. Some of the most-used features in mature AI products weren’t on any roadmap. They were someone noticing that something they assumed wouldn’t work suddenly did, and shipping it in a week.
Demo first, document second. The traditional sequence — research, spec, PRD, handoff, build — optimises for certainty at the expense of speed. It works when discovery is front-loaded and technology is stable. In an environment where capability shifts mid-project, you want to move the “does this actually work?” question as early as possible. Prototype-first culture does that. A rough working demo surfaces real constraints — and real possibilities — faster than any written spec. When a prototype takes an afternoon, wrong bets cost almost nothing. That changes what you’re willing to try.
Revisit features with every model upgrade. Most teams have a one-way relationship with shipped features: ship, move on, only revisit if something breaks. That made sense when capability was stable. Now, each model release is effectively a prompt to go back through your existing feature set and test assumptions again. Something that needed significant scaffolding to work acceptably three months ago might now just work, cleanly, out of the box. The teams catching this systematically have a repeatable advantage over teams that only look forward. Being a daily active user of your own product — and deliberately pushing at the edges of what you think is possible — is how you notice these moments.
Do the simple thing. This is the most counterintuitive shift because it cuts against the PM instinct to engineer solutions to known problems. When a model has a limitation, the natural response is to design around it — add reminders, add guardrails, add logic to compensate. That works. But it also creates a liability: the next model likely doesn’t have that limitation, and now you’re maintaining a workaround for a problem that no longer exists. The simpler your implementation, the easier it is to benefit from capability improvements when they arrive. Clever hacks have expiry dates. Simple designs don’t.
The new rhythm: a shorter loop
What these four shifts share is a change in cadence. The old PM rhythm was: explore → plan → execute → ship. Long cycles, front-loaded discovery, stable execution phases. The new rhythm is a tighter loop that runs continuously alongside whatever the official roadmap says.
The loop — experiment, demo, ship, revisit — isn’t a replacement for strategy. It’s the mechanism by which strategy stays accurate. You still need a clear sense of where you’re going and why. What changes is how tightly that direction connects to what’s currently possible, and how quickly you update when the ground shifts.
Notice what triggers each transition. You move from experiment to demo when something generates genuine engagement, not just when it hits a milestone date. You move from demo to ship when it validates cleanly with real users. You move from ship to revisit when a new model drops — not just when users complain. And you move from revisit back to experiment when you discover a constraint has flipped. Model upgrades become a scheduled trigger in your process, not an interruption.
What this means for the Builder-PM specifically
In stable-technology environments, PM value came from reducing uncertainty upfront: thorough discovery, comprehensive specs, confident roadmap bets. That instinct doesn’t disappear — you still need strategic clarity. But it’s no longer sufficient on its own.
In a world of exponential model improvement, the complementary skill is detecting when the constraint you built around has disappeared — and reorganising faster than the competition does. That requires proximity to the technology, not just proximity to the customer. You need to be testing the model regularly, not just reviewing the research.
The PM’s job is now to create clarity in the ambiguity that rapid model progress creates, push the team to think bigger about what’s possible, and clear the path to shipping faster. That’s a different kind of clarity than a traditional roadmap provides — it’s continuous, not front-loaded.
If you’re a builder-PM — someone who moves between the product layer and the implementation layer — this is actually a structural advantage. You’re positioned to notice capability flips faster than a PM who only reads research summaries, because you’re close enough to the model to feel them. The side quest isn’t a distraction from your core work. In this environment, it might be the most strategically valuable hour of your week.
The most important thing to internalise is that the ground rising is not a problem to be solved. It’s a permanent condition. The teams that perform best on an exponential aren’t the ones who found a way to stop the ground from moving. They’re the ones who built short enough loops to keep their footing as it does.
This piece was prompted by a post by Cat Wu, Head of Product for Claude Code at Anthropic. The ideas here are my own analysis, building on the patterns she identified.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organisational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.