
The AI Agent Pricing Map: Seven Models, One Market, No Convergence yet...

Seven incompatible pricing models, one market, no convergence yet. What researching the cost of 50 AI agents reveals about a category that doesn’t know how to value itself yet.

SaaS had a standard pricing model. You bought seats. Everyone understood it. A 50-person company paying for Salesforce knew exactly what it would cost next year, and the year after that. The contract was predictable. The renewal was a negotiation over percentage points.
AI agents broke that contract. Not by accident — by design. The moment a piece of software starts taking autonomous actions on your behalf, the question of what you’re actually paying for becomes genuinely hard to answer. Are you paying for access? For compute? For outcomes? For the number of things the agent did? For the minutes it spent on the phone? Nobody has settled on an answer, and the evidence across 50 companies is that nobody is close to settling.
What follows is what I found when I mapped the pricing models of 50 AI agent companies across customer service, coding, voice, sales intelligence, legal, HR, and developer tooling. The picture is not chaos exactly — but it is seven incompatible bets about where agent value actually lives, all running simultaneously, with real money on each one.
The seven archetypes
Every AI agent company in this dataset fits, roughly, into one of seven pricing shapes.
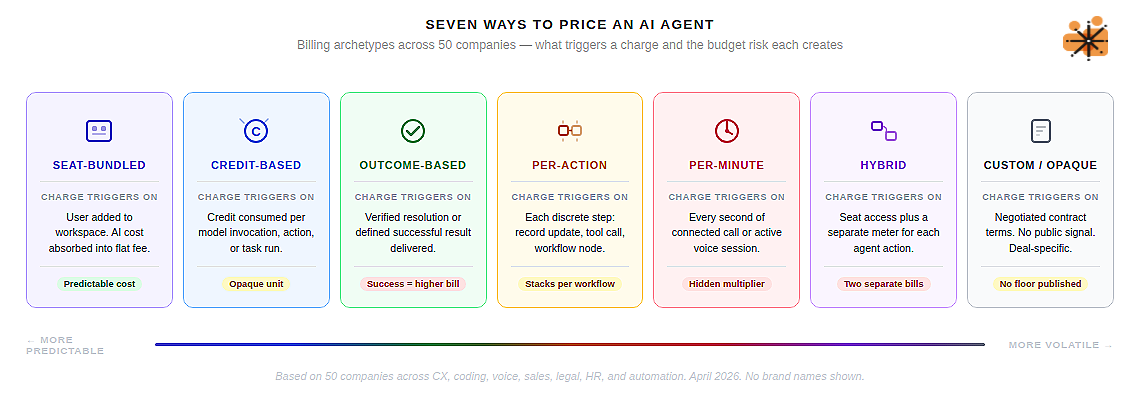
Seat-bundled
AI capabilities are absorbed into the per-user licence fee and the consumption underneath is invisible. Notion, Dust.tt, Linear, Jasper, Otter.ai — these companies for example have bet that customers will accept AI as a feature of the seat, the same way they accept cloud sync or mobile access.
The economics work until you ask what happens to margin when a power user runs agents for six hours a day. The answer is usually “fair use policy,” which is a polite way of saying “we’ll throttle you without warning.”
Credit-based
A proprietary currency that abstracts the underlying token cost. Cursor gives you $20 of credits with your $20 Pro subscription. Clay separates Data Credits from Actions. Relevance AI splits Actions from Vendor Credits.
The credit system is elegant in theory — one number to manage, one pool to budget — but in practice it creates a new opacity. What is a credit worth in real terms? The answer changes depending on which model you invoke, which workflow you run, and which features you enable.
Outcome-based
The model everyone discusses at conferences and almost nobody actually uses at scale. Intercom Fin charges $0.99 per resolved conversation. HubSpot Breeze moved to $0.50 per resolved conversation in April 2026. Sierra charges per successful outcome at enterprise scale.
The logic is compelling: you only pay when the agent delivers value. The problem, as we’ll get to shortly, is that “resolution” is a contested concept, and the financial exposure when your agent performs well is unbounded.
Per-action
Paying for each discrete step the agent takes. Salesforce‘s Flex Credits charge $0.10 per action — updating a record, summarising a case, answering a query. n8n charges per workflow execution. CrewAI charges per agent run.
The appeal is granularity: you can see exactly what you’re paying for. The risk is that complex agent tasks decompose into many small actions, each of which triggers a charge, and the bill for a single business outcome can stack unexpectedly.
Per-minute
Dominates voice AI and has almost no presence elsewhere. Bland AI, Synthflow, Retell AI, Vapi — all price by the connected minute. The logic is borrowed from telecom: a call is metered, a call has a duration, a duration is priced.
Clean and familiar. The complication is that a voice AI “minute” is not a single cost — it is a stack of four or five independent costs, each from a different vendor, and only the top of that stack appears in the headline rate.
Hybrid Model
Two or more models running simultaneously on the same product. Microsoft Copilot charges $30/user/month for humans and Copilot Credits for agent actions. Salesforce Agentforce runs conversation fees and per-action Flex Credits and per-user licences concurrently. Zapier bills Tasks for automations and Activities for agents.
These hybrid models are often the result of a company trying to serve both a known buyer (who wants seats) and a new reality (where the agent does the work).
Custom Models
No public pricing, enterprise negotiation only. Harvey AI estimates at $1,000–1,200 per lawyer per month and won’t confirm it. ServiceNow‘s AI Assists model adds hundreds of thousands of dollars to existing enterprise contracts without a published rate card. Glean starts at $50+/user/month with a 100-seat minimum. The opacity is sometimes a deliberate pricing strategy; sometimes it reflects genuine uncertainty about what the product is worth in a market that hasn’t formed a consensus yet.
The migration that’s already happening
The most revealing data in this research isn’t the static snapshot — it’s the movement. Twelve companies made significant pricing model changes in 2025 and early 2026, and almost all of them moved in the same direction: away from flat, predictable seat pricing and toward something more consumption-linked.
Microsoft retired its standalone Copilot for Sales, Service, and Finance SKUs in late 2025. Salesforce, having launched Agentforce at $2 per conversation in late 2024, pivoted to Flex Credits at $0.10 per action in May 2025 after customers complained they couldn’t define what a “conversation” meant in the context of a complex multi-step workflow. Zendesk moved from monthly active users to $1.00–$2.00 per automated resolution. HubSpot moved its mature Breeze agents from credits to outcome pricing. Outreach launched an “Amplify” packaging with AI action credits sitting on top of per-user rates.
Gong‘s March 2025 restructure unbundled its previously all-inclusive $1,600/user seat into modular components — Foundations, Engage, Forecast — while quintupling the platform fee from $10,000 to $50,000 per year. Customers paying the same or more now own less, and each AI capability is a separately negotiated add-on. It is a pricing restructure designed to capture the value of AI features rather than bundle them as an implied benefit of the base product.
Devin‘s price collapse tells a different story. Cognition launched the “world’s first AI software engineer” at $500/month — a price that implied enormous autonomous value — then dropped to $20/month plus pay-as-you-go Agent Compute Units in April 2025 after the market refused to validate the premise. The original price had no relationship to what the product could reliably deliver. The correction was not a strategic pivot; it was a market verdict.
“The hardest thing in AI pricing right now is that the value is real, the cost is real, but the unit of value nobody agrees on.” — Foundation Capital, 2026 outlook
What the migration reveals is a market in active price discovery. Vendors are not moving toward consumption pricing because they’ve worked out the right model. They’re moving because seat pricing was designed for software that doesn’t do work autonomously, and that limitation is becoming increasingly obvious.
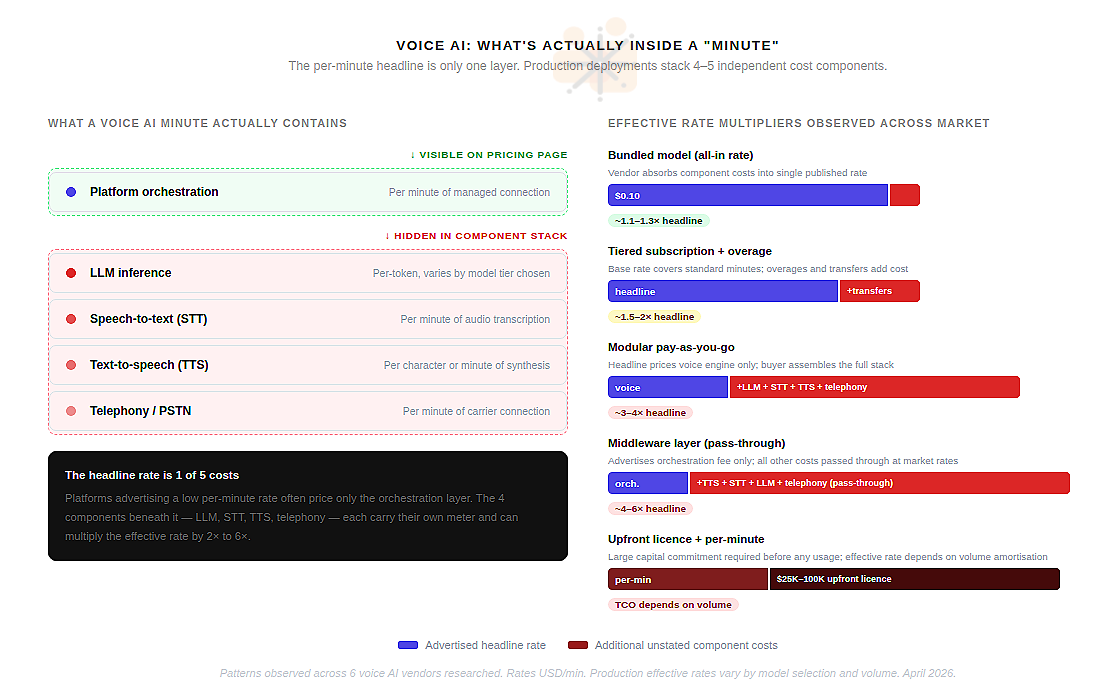
Voice agents and the per-minute illusion
Voice AI is the one segment of the agent market where pricing has converged on a common unit: the connected minute. Bland AI, Synthflow, Retell AI, Vapi, Air AI — all of them advertise per-minute rates. The logic is borrowed directly from telecom. Clean and familiar.
The problem is that a voice AI “minute” is not a single cost — it is a stack of four or five independent costs, each from a different vendor, and only the top of that stack appears in the headline price. A Vapi call costs $0.05/min for the Vapi orchestration layer. It also costs $0.01–$0.06/min for text-to-speech, $0.01/min for speech-to-text, a per-token fee for the LLM processing the conversation, and $0.005–$0.014/min for telephony. The advertised $0.05 becomes $0.13–$0.33 in practice. The multiplier is 3 to 6 times the headline.
Retell AI is explicit about this. Their pricing page lists six separate components — voice engine, LLM, STT, TTS, knowledge base, telephony — each with its own rate. The advertised “from $0.07/min” refers exclusively to the voice engine. A production deployment runs $0.13–$0.31/min depending on model choices. This is not a bait-and-switch; the information is there. But a buyer accustomed to reading a SaaS pricing page is not reading it as a component cost sheet.
Air AI represents the most extreme version of this problem. The platform requires a $25,000–$100,000 upfront licence before any per-minute charge applies. Multiple sources report unresolved billing disputes and platform degradation through 2025. The per-minute rate is the least important number in the cost structure.
ElevenLabs moved in the opposite direction — a clean $0.10/min announced in December 2024 for conversational AI agents, absorbing the component complexity into a single published rate. It is the most legible voice AI pricing in the market. Whether the margin works at that rate at scale is a separate question, but the customer experience of buying is unambiguous. That is a meaningful competitive choice, not just a pricing tactic.
The Bland AI December 2025 restructure is the cautionary data point. The company moved from a flat $0.09/min to tiered rates of $0.11–$0.14/min — a 22–56% increase. Community backlash was significant. The lesson: customers who have built production infrastructure on top of a vendor’s rate card experience a cost model change as a breach of trust, not a commercial adjustment.
For any organisation deploying voice agents at scale: the headline rate is a floor, not a ceiling. Budget from the effective rate of a real test deployment, not from the pricing page.
The Outcome Paradox
Of the seven archetypes, outcome-based pricing generates the most enthusiasm in product discussions and the most discomfort in finance discussions. The idea is elegant: you pay only when the agent succeeds. Zero value delivered, zero charge.
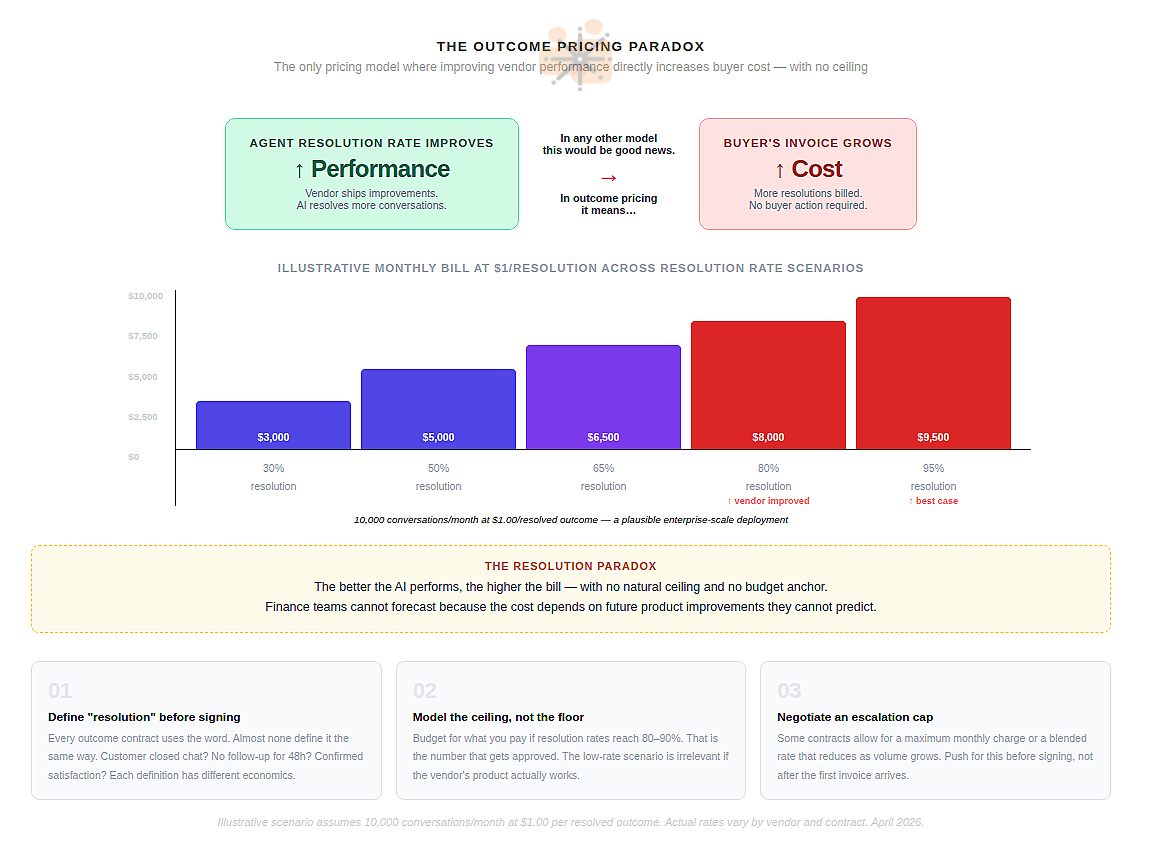
In practice, it contains a structural problem the industry has not resolved. When an outcome-based agent performs well, costs increase. There is no natural ceiling. A team running 10,000 conversations per month with Intercom Fin at a 60% resolution rate pays $5,940 per month. If resolution rates improve to 80% — because Intercom improved the product, not because the team did anything — the bill becomes $7,920. A 33% increase from a vendor improvement the customer never requested.
Ada AI published a thoughtful argument against its own industry’s per-resolution pricing model, describing it as a structure that “punishes success.” Klarna‘s 2025 reversal from an all-AI support model — after credible claims of $60M in savings — came after customer complaints about generic AI responses. The savings were real. The CSAT damage was also real.
Replacing human judgment with measurable outcomes is harder than the pricing model implies.
The resolution paradox reflects a deeper unresolved question: what is the right unit of value for an autonomous agent? A resolved conversation is a reasonable proxy. But it is a proxy, not the thing itself. At enterprise scale, the gap between the vendor’s definition of “resolved” and the buyer’s definition of “customer satisfied” is where contracts go to die.
What no convergence actually means
The absence of a dominant pricing model is not a sign of market immaturity in the usual sense. Cloud infrastructure took years to converge on per-instance-hour. SaaS converged on per-seat with remarkable speed in the early 2010s. In both cases, convergence happened because the underlying value unit was obvious.
For AI agents, the underlying value unit is genuinely contested because the thing being sold is genuinely new. A voice agent that replaces a call centre operator creates value measured in human hours avoided. A coding agent creates value measured in shipping velocity. A legal AI creates value measured in billable time recaptured. A customer service agent creates value measured in resolution rate and CSAT. These are not the same unit, and a pricing model that works for one will misrepresent the value of another.
The practical implication for buyers: every purchase decision is also a bet on a value definition. When you sign an outcome-based contract, you are agreeing that “resolution” is the right measure of value for your deployment. When you accept a credit-based contract, you are accepting that compute consumption is a reasonable proxy for business output. Each of these assumptions can be wrong in ways that are expensive to discover after the contract is signed.
The question isn’t which pricing model is best. It’s which model’s definition of value matches your definition of value — and whether you can measure the gap before you sign.
The companies best positioned as this shakes out are not the ones with the lowest headline rates. They are the ones that make the link between spend and outcome legible before the invoice arrives — that instrument their agents at the outcome level, not just the token level, so that the CFO question and the product question have the same answer. That instrumentation doesn’t exist natively on most platforms today. It is the gap that the next wave of AI infrastructure tooling will fill.
Seven models. Fifty companies. No consensus. The market is still working out what intelligence is worth — and right now, every vendor is answering differently.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organisational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.