
Claude Managed Agents: Is this for everybody building Agents?

Anthropic launched Claude Managed Agents this week. The announcement is well-made, the positioning is clear, and the product addresses a real pain point — for a specific kind of team. The problem is that most of the conversation online has treated it as a universal unlock rather than a targeted solution. That’s worth correcting.
Managed Agents is an infrastructure layer. It handles the operational complexity of running AI agents at scale
sandboxed execution environments,
session persistence across network interruptions,
credential management,
scoped permissions, progress tracking, and error recovery.
These are genuinely hard problems. They take months to build correctly, and most teams who skip them discover exactly why that was a mistake when they hit production.
The service is clean, the pricing is simple, and the abstraction is well-designed. Anthropic’s engineering team framed it as a “meta-harness” — deliberately stable interfaces that survive model capability changes, in the same way that OS abstractions outlasted decades of hardware evolution. That’s a real insight, and it’s a thoughtful way to build.
But here’s the thing: if you’ve spent serious engineering time building production agents, you’ve very likely already solved the core problems this service addresses. Not in the same way, not with the same APIs — but solved them.
What problem does it solve exactly?
The central problem Managed Agents fixes is state management decoupled from the LLM’s context window. A long-running agent can’t keep everything in memory. If it tries to, context fills up, coherence degrades, and you either hit the limit or start compressing. The solution is to write intermediate results to persistent storage — and read them back selectively as needed. Your agent loop becomes less of a monologue and more of a conversation with its own working memory.
If you’ve shipped a production agent, you almost certainly have some version of this. A file-based working directory in object storage. A database that carries status and flags. A pattern where the agent writes section outputs as it goes, rather than accumulating everything in context until the final moment. The specific implementation differs. The architecture doesn’t.
The same is true for progress tracking. Managed Agents surfaces agent progress without requiring the agent to self-report. That’s a smart design — explicit status calls add cognitive overhead and create drift when the agent forgets to call them. But if you’ve shipped agents, you’ve likely solved this too. The most robust version is to derive status from what the agent actually does: file writes, database updates, queue events. Actions become the signal. You don’t ask the agent where it is — you observe what it’s produced.
The target customer for Managed Agents is the team facing months of infrastructure work before they can ship anything. If that’s not you, the calculus looks different.
Error containment is another one. Managed Agents handles recovery from failures — network interruptions, tool errors, runaway loops. Any team that’s run agents in production has built their own version of this, because the first time a two-hour research job fails at step 47 and restarts from zero, you build recovery fast. Tool-level error containment, hard caps on agent steps, graceful degradation when data isn’t available — none of these are exotic. They’re the hard-won lessons of anyone who’s shipped.
Three team profiles, three different answers
The honest question to ask is: which problems on Managed Agents’ feature list are problems you haven’t solved yet? Not which problems they solve better — which ones are still open for you? The answer maps cleanly onto where a team sits across two dimensions: how much agent infrastructure they’ve already built, and the operational complexity they’re facing.
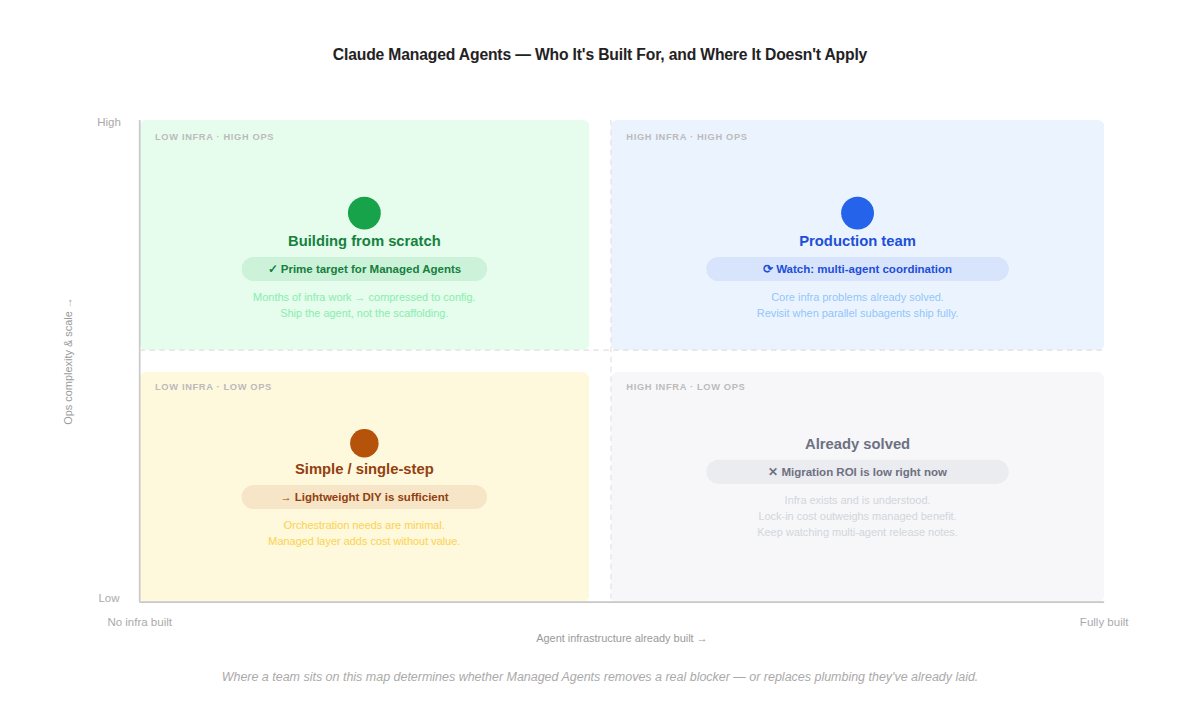
Where a team sits on this map determines whether Managed Agents removes a real blocker — or replaces plumbing they’ve already laid.
If you’re early — building your first production agent, still at proof-of-concept, not yet confronting the sandboxing and credential questions — Managed Agents is genuinely worth adopting. The full list of what you’d otherwise have to build is sobering:
Sandboxed execution environments so the agent can’t touch production systems
Session persistence so a network interruption doesn’t restart a two-hour job from zero
Credential management and scoped permissions per tool
Tool orchestration, error recovery, and step-limit enforcement
End-to-end tracing so you can diagnose what went wrong at step 47 of 60
None of this is interesting engineering. It’s all necessary, and it all takes time. Managed Agents collapses that into configuration and an API header. You skip the accidental learning — the lessons you only get by hitting production with incomplete scaffolding — and go directly to building what your agent actually does. There’s also a structural benefit that compounds over time: as Claude’s model behaviour changes and the assumptions baked into your harness go stale, Anthropic absorbs that churn. The abstraction layer is designed to outlast any particular model generation.
Teams with lightweight orchestration needs — a single tool call, a short agentic loop, no persistent state across sessions — sit at the opposite end and get very little from Managed Agents, but for a different reason. The platform is designed for operational complexity that these workflows simply don’t generate. Long-running session persistence doesn’t matter if your agent completes in thirty seconds. Sandboxed container execution is overhead if your agent is calling one external API. The managed layer adds cost — $0.08 per session hour on top of token rates — and introduces vendor dependency without adding meaningful capability. The instinct to use a managed platform as a default because it signals seriousness is a trap here. The right infrastructure for a simple workflow is simple infrastructure.
Teams that have already shipped production agents face the most nuanced calculation. The objection isn’t that Managed Agents is poorly designed — it isn’t. The objection is that the problems it solves are problems you may have already solved, and also calibrated to your specific workload:
You know your failure modes because you’ve seen them in production
Your state management is tuned to your agent’s actual working pattern — what it writes, when, and what it reads back
Your error containment is calibrated to your specific tool set and loop structure
A managed layer replaces all of that institutional knowledge with vendor defaults. You’re not gaining capability; you’re trading understood complexity for uncharted complexity, and adding lock-in in the process. The migration cost isn’t just engineering time — it’s the cognitive overhead of re-learning your own system’s behaviour through someone else’s abstraction.
Scaling is the counterargument most often raised here: surely a purpose-built managed service handles burst demand more gracefully than a home-built queue and container setup?
In practice, this conflates an architectural problem with an operational one. A queue-backed container architecture scales by raising concurrency limits and letting the orchestrator absorb demand — that’s a configuration change, not a re-architecture. If burst capacity is exposing genuine gaps in your current setup, the answer is to fix the configuration, not to migrate the entire agent runtime to a new platform. Solving an ops problem with an architectural migration is almost always more expensive than it looks.
The one thing worth watching
There is a feature in Managed Agents that could genuinely change the calculus for teams who’ve already built their own stack. It’s not available yet — it’s in research preview — but it’s worth tracking closely.
Multi-agent coordination: the ability to fan out parallel subagents that communicate directly, run in isolated contexts, and report results back to an orchestrating agent.
For any workflow that currently executes tool calls sequentially inside a single agent loop, this is a meaningful architectural upgrade. Independent data queries that currently run one after another could run simultaneously. The stitching phase could coordinate multiple specialised agents rather than a single generalist. Wall-clock time drops; complexity of the problem space expands.
The reason this is different from the rest of the Managed Agents feature set is that it’s not solving a problem most teams have already solved. Building multi-agent coordination yourself is genuinely hard — the communication patterns, shared task management, and error handling across parallel contexts are non-trivial. If Managed Agents ships this cleanly, it becomes a real conversation about whether the architectural gain is worth the migration cost.
That’s the moment to revisit. Not the launch announcement.
The underlying pattern
What Managed Agents represents strategically is Anthropic’s move from model API provider to full-stack agent platform. That’s a significant shift, and it’s worth paying attention to for that reason alone. The interfaces they’re building — stable abstractions designed to outlast model capability changes — reflect genuine systems thinking. The engineering blog post on how harness assumptions go stale as models improve is worth reading regardless of whether you use the product.
But “this is a thoughtfully designed platform” and “this solves a problem you have right now” are different questions. The former is true. Whether the latter applies to you depends entirely on where you are in building your own stack.
The teams who benefit most from Managed Agents are the ones who would otherwise spend the next three months building what teams with production agents have already built. For everyone else: read the engineering post, watch the multi-agent coordination release notes, and resist the pressure to migrate toward infrastructure that no longer represents an open problem for you in entiriety.
The author is building Auron — an AI-powered voice and conversation intelligence platform that captures and enriches organisational knowledge from meetings, calls, and conversations. Auron turns every interaction into structured signal that teams can act on.