
AI products have failure modes. PMs need a new language for them
The vocabulary we borrowed from software engineering is quietly sabotaging how we build, communicate, and ship AI products.

When a traditional software product breaks, you file a bug. The logic was wrong. The API returned a 500. The button didn’t submit the form. The fix is deterministic — find the bad line, change it, ship it.
AI products don’t work that way. And if you’re managing one using the same mental model, you’re already behind.
The Bug Metaphor Is Broken
A bug implies a binary state: broken or working. It implies a root cause. It implies a fix that closes the ticket.
AI failures are none of those things. When a voice agent gives a confident but incorrect answer, that’s not a bug. When a signal extraction model misclassifies intent 12% of the time, that’s not a bug. When a summarization pipeline produces something technically accurate but strategically useless — that’s definitely not a bug.
These are failure modes — probabilistic, context-dependent, often invisible until they compound. Calling them bugs sets the wrong expectation with stakeholders, routes them to the wrong owner, and frames the solution incorrectly. “We’ll fix it next sprint” is the wrong answer to a confidence miscalibration problem.
“Correct” is a distribution, not a binary. The PM’s job is to understand that distribution and narrow it — not hunt for a root cause that doesn’t exist.

A Working Vocabulary for AI Failure Modes
Here’s a practical taxonomy PMs and their teams should be operating with. Name these things. Put them in your PRDs. Use them in standups.
01 — Confidence Miscalibration
The model outputs an answer with high implied confidence but is wrong. This is particularly damaging in user-facing contexts because users make decisions on that confidence signal. The fix isn’t “make it right” — it’s recalibrate thresholds, surface uncertainty in the UX, or constrain the output domain.
Intelligence Extractor
Every extracted signal for example carries a float confidence score (0–1). Signals below 0.3 are discarded and never surfaced. That’s a deliberate design policy — not a patch. The cutoff is a managed failure mode boundary, not an error handler.

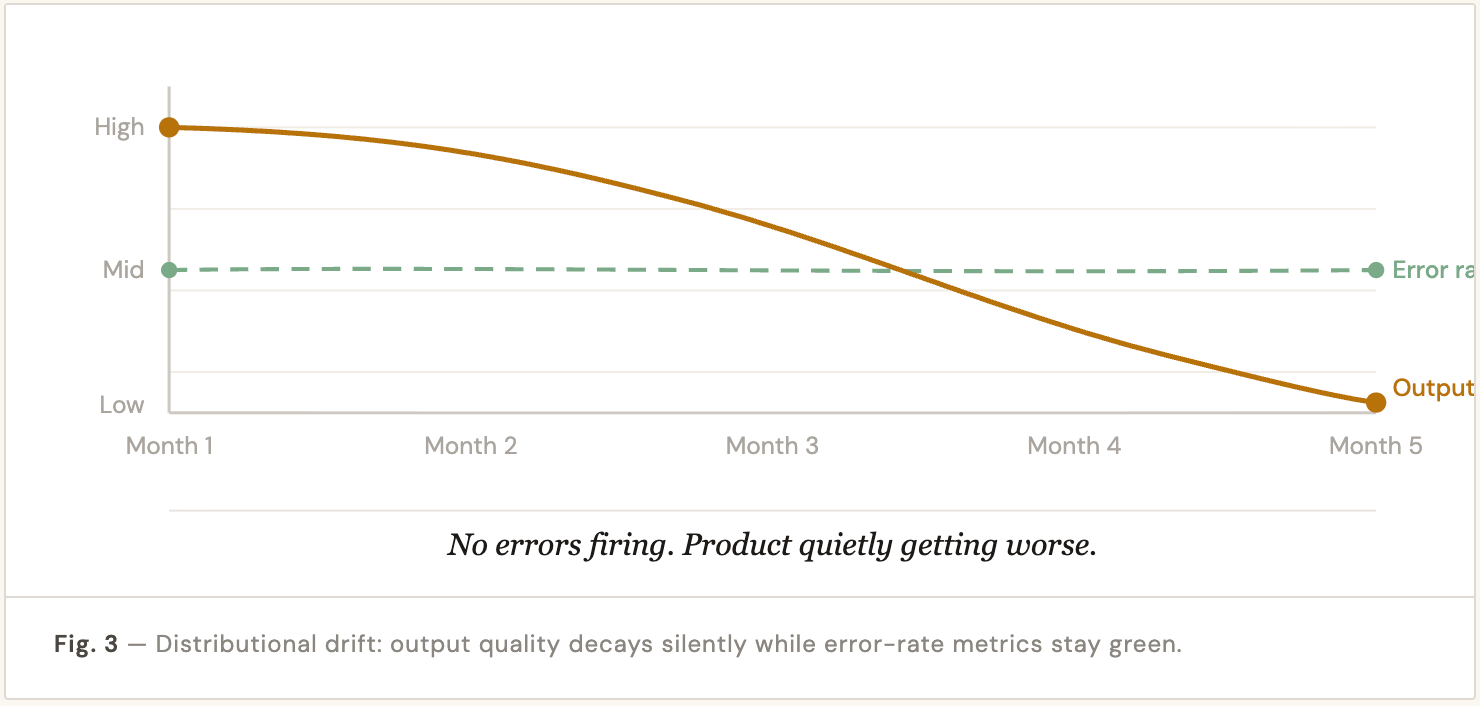
02 — Distributional Drift
The model was trained or prompted on one kind of input and is now seeing inputs that look subtly different. Performance degrades quietly. No errors, no alerts — just slowly declining quality. Your dashboards look fine. Your product is getting worse.
Voice Agent
A voice agent tuned on structured sales debriefs behaves differently on open-ended discovery calls. The signal shapes are different, the utterance patterns are different. Drift here isn’t caught by error logs — it’s caught by reviewing signal density and extraction quality across call types over time.
03 — Context Collapse
The model’s behavior changes based on what’s in the context window in ways that aren’t obvious or predictable. In agentic systems, earlier conversation turns, injected prompts, or retrieved chunks can silently reshape downstream outputs in ways that are extremely difficult to trace.
Agent Constitution
The Agent Constitution explicitly separates what the real-time Conversation Agent accesses versus what the post-call Signal Extractor processes. This isn’t just an architecture call — it’s a direct mitigation for context collapse. Letting both agents share a live context window was a failure mode waiting to happen.
04 — Hallucinated Grounding
The model produces an output that is internally coherent but externally false — and implies a source it doesn’t have. In RAG-based systems, this often shows up as the model confidently synthesizing across documents in ways that weren’t intended, producing something that sounds rigorous but isn’t traceable to anything real.
05 — Graceful Degradation Failure
The system doesn’t know what it doesn’t know. Instead of flagging a low-confidence situation or falling back to a safe default, it proceeds as if it does know. This is a design failure, not a model failure — it means the failure surface wasn’t anticipated at the product level.
06 — Evaluation Blindspot
Your evals are passing. Your product is still bad. The metrics you’re using to measure quality don’t capture the failure mode that actually matters to users. This is one of the most expensive failure modes in AI product development — not because it’s hard to fix, but because it’s hard to detect. You have to notice the gap between what you’re measuring and what your users actually need.
What This Means for PMs
Write failure modes into your PRDs, not just acceptance criteria.Every AI feature should answer: How does this fail? At what rate is that acceptable? How will we detect it? If you can’t answer those before you ship, you’re not ready to ship.
Build a failure mode taxonomy for your product.A voice agent has a different failure surface than a document classifier. Document them, name them, make your whole team speak the same language.
Create visibility for silent failures.Most AI failure modes don’t throw errors. They produce the wrong output quietly. This means intentional observability: human review queues, signal quality dashboards, confidence distribution monitoring, user feedback loops. If your only signal is error rate, you’re blind.
Decouple “working” from “correct.”An AI system that returns outputs consistently without errors is working. It may still be wrong a meaningful percentage of the time. Hold both truths simultaneously and communicate that distinction clearly to stakeholders.
Triage by failure mode, not severity alone.A hallucination in a customer-facing context is a different kind of problem than distributional drift in a back-office pipeline — even if both look like “the AI was wrong.” The response, the owner, and the fix are completely different.
The Mindset Shift
Managing AI products well requires giving up the comfort of determinism. There is no version of your AI product where failure reaches zero — because “correct” is a distribution, not a finish line.
The vocabulary you use internally is the first step. When your team starts saying “confidence miscalibration” instead of “the AI was wrong,” and “evaluation blindspot” instead of “we didn’t catch it in testing” — you’re thinking about the problem correctly.
And here’s the uncomfortable part: most AI teams aren’t. They’re filing bugs, closing tickets, and reporting green dashboards while their products quietly fail in ways their metrics were never designed to catch.
The PMs who get this right won’t just ship better AI products. They’ll be the ones who can honestly tell their stakeholders what their system does well, what it doesn’t, and why that’s a feature of the medium — not a failure of the team.